Causal Role Classification: How I Beat the ADIA Lab Top-1 Solution
This writeup describes the solution I developed for the ADIA Lab Causal Discovery Challenge as part of my BSc thesis at VNU-UET (2026). The solution achieves 81.14% balanced accuracy locally and 80.82% on the CrunchDAO public leaderboard, surpassing the original competition top-1 result of 76.70% by +4.12%.
A second post will cover the Conv2D / 2D scatter density extension (v26).
Disclaimer
A few things to be upfront about before the technical content.
I had prior knowledge of the competition through the ADIA Lab survey paper, which describes the data-generating process. I did not use this to generate synthetic training data - that would invalidate the scientific contribution.
My solution is built directly on top of the top-1 competition writeup as a baseline. I also take advatange of EDA insights and data augmentation from the 3rd-place writeup. The novelty claims in this post are incremental improvements on top of that foundation - I’d rather be honest about that than oversell it.
This blog post is written by Claude with me as a proof reader and editor. The technical content is my work, but the writing style is a collaboration.
All the source code for this project is available in this repository. All the experiments result is available in this Google Sheet.
Problem Setup
Given $n = 1000$ observations of $p \in {3, \ldots, 10}$ variables, where a causal edge $X \to Y$ is always known to exist, classify every other variable $K$ into one of 8 causal classes:
| Role | Graph motif |
|---|---|
| Confounder | $X \leftarrow K \rightarrow Y$ |
| Mediator | $X \rightarrow K \rightarrow Y$ |
| Collider | $X \rightarrow K \leftarrow Y$ |
| Cause of X | $K \rightarrow X$ (no edge to $Y$) |
| Cause of Y | $K \rightarrow Y$ (no edge to $X$) |
| Consequence of X | $X \rightarrow K$ (no edge to $Y$) |
| Consequence of Y | $Y \rightarrow K$ (no edge to $X$) |
| Independent | No edge to $X$ or $Y$ |
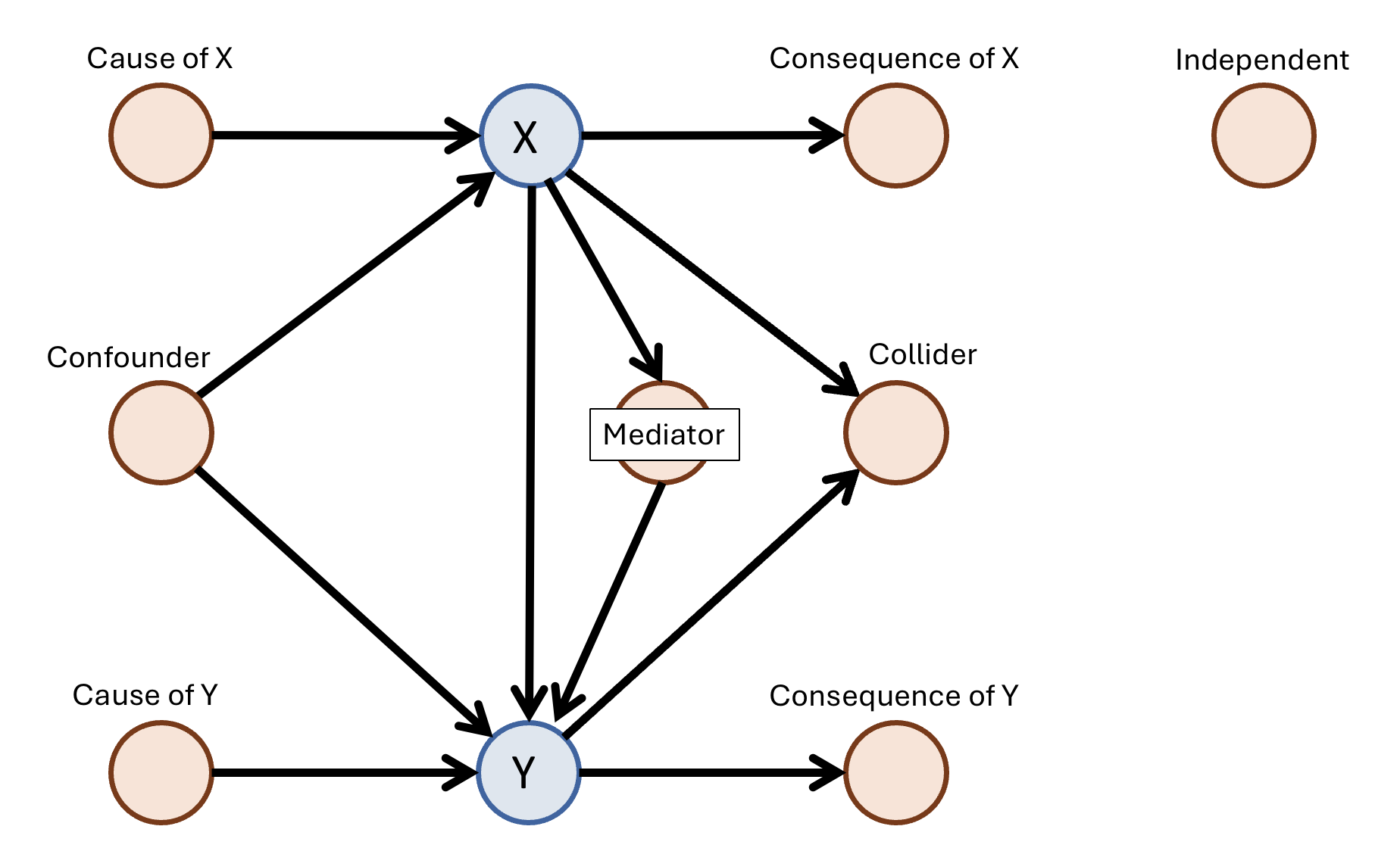 The 8 classes (image from the ADIA Lab paper)
The 8 classes (image from the ADIA Lab paper)
Metric: balanced accuracy - mean per-class recall. Overall accuracy is never reported. The hardest classes are Collider and Mediator; they count equally with the easy ones.
Baseline: The Top-1 Solution
The top-1 solution’s core insight is representing each variable pair as a sorted observation curve rather than a set of scalar statistics.
For a variable pair $(u, v)$ with $n$ observations, sort the observations by $u$’s values and read how $v$ changes across that ordering. This gives a length-$n$ sequence - a functional relationship curve - that captures nonlinear conditional structure that any scalar summary (correlation, partial correlation) permanently discards.
Three channels are constructed per edge $(u, v)$:
\[\mathbf{c}_1 = \text{sort}_u(u), \quad \mathbf{c}_2 = \text{sort}_u(v), \quad \mathbf{c}_3 = \hat{\beta}(v \mid \text{all variables})\]where $\mathbf{c}_3$ is a multivariate kernel regression coefficient - predicting $v$ from all other variables simultaneously using a Gaussian kernel on full-row distances. This captures conditional (not just pairwise) dependencies.
A Conv1D encoder processes these 3-channel sequences into edge embeddings. A self-attention layer then aggregates over all $O(p^2)$ edge pairs in the graph, allowing global graph reasoning. A node head produces the final 8-class prediction.
My reimplementation: 73.96% local / 73.6% leaderboard (vs. claimed 76.70%). The gap is likely due to implementation details not fully specified in the writeup.
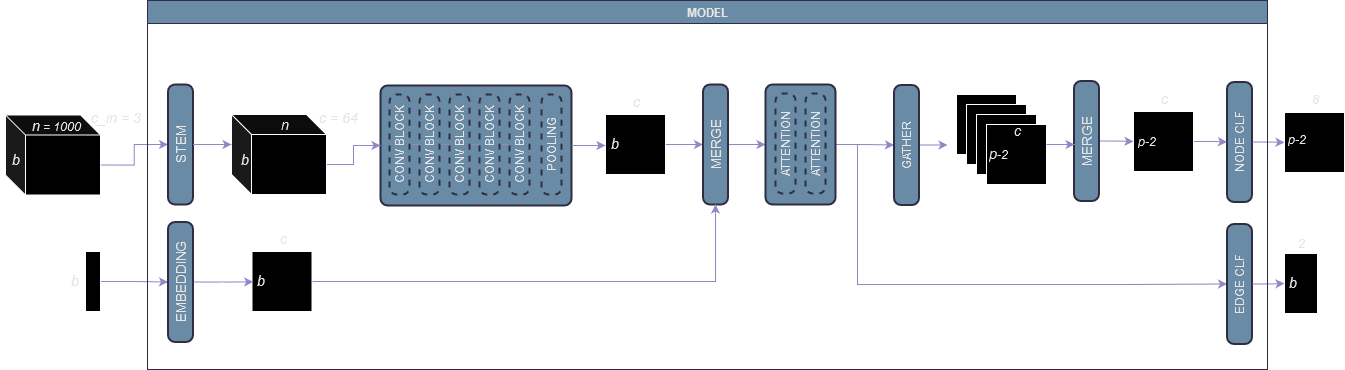 The baseline architecture (image from the top-1 writeup)
The baseline architecture (image from the top-1 writeup)
Contribution 1: Increase Input Channels
1.1: Multi-Bandwidth Kernel Channels
The baseline uses a single kernel bandwidth for the multivariate regression coefficient. A single bandwidth creates a bias-variance tradeoff: coarse bandwidth ($h$ large) smooths away local nonlinear structure; fine bandwidth ($h$ small) is noisy.
I add two more channels using kernel regression at different bandwidths ($h \in {0.2, 0.5, 1.0}$), giving the model access to both local and global conditional structure simultaneously:
\[\mathbf{c}_{1..5} = [\text{sort}_u(u),\ \text{sort}_u(v),\ \hat{\beta}_h(v)_{h=0.2},\ \hat{\beta}_h(v)_{h=0.5},\ \hat{\beta}_h(v)_{h=1.0}]\]Result: 73.96% → 75.44% (+1.48%)
1.2: ANM Residual Channels
The Additive Noise Model (ANM) framework [Hoyer et al., 2009] states: if $X$ causes $K$, then the residuals of regressing $K$ on $X$ should be statistically independent of $X$. If the direction is reversed, independence does not hold.
This asymmetry is a direct signal of causal direction - exactly what separates many of the 8 classes. I compute ANM residuals for each variable pair direction and add them as 3 additional channels (at multiple bandwidths, $\sigma \in {1.0, 2.0, 4.0}$):
\[\mathbf{c}_{6..8} = [\epsilon_{u \to v}(\sigma=1.0),\ \epsilon_{u \to v}(\sigma=2.0),\ \epsilon_{u \to v}(\sigma=4.0)]\]where $\epsilon_{u \to v}$ is the residual of kernel-regressing $v$ on $u$, sorted by $u$.
Why this helps specific classes: Collider ($X \to K \leftarrow Y$) and Consequence of X ($X \to K$) are the clearest beneficiaries - both involve $X$ causing $K$, and the ANM residual of $K$ regressed on $X$ should be near-independent of $X$. The reverse direction residual is not. The model learns to read this asymmetry.
Result: 75.44% → 76.94% (+1.50%). Combined with XY augmentation: 80.26% / 80.22% LB.
 The modified input tensors
The modified input tensors
Contribution 2: XY Augmentation (Idea from top-3 writeup)
In the original setup, the model always sees each graph with fixed $(X, Y)$ identities. This creates a risk of learning positional shortcuts - “when I see this pattern, $X$ is usually in position 0” - rather than learning the underlying topology.
XY augmentation remaps variable labels so the same graph structure is presented from multiple $(X’, Y’)$ perspectives during training. For a graph with $p$ variables, there are roughly 11 valid relabelings on average. This forces the model to learn the role of each variable relative to the edge structure, not relative to fixed labels.
The augmentation multiplies the effective training set size by ~11× (from 25K graphs to 263K augmented samples).
Interaction with structural bias: When applied on top of v11 (structural attention bias), XY augmentation gave only +1.55% vs. +3.32% on earlier versions. The reason: both techniques encode topological structure - one architecturally, one through data. Once the model has the structural prior, the augmentation has less new information to contribute. This partial redundancy was indirect evidence that the structural bias mechanism is functioning correctly.
 Demonstration of the augmentation process (image from top-3 writeup)
Demonstration of the augmentation process (image from top-3 writeup)
Contribution 3: Structural Attention Bias
This is the only architectural change that produced a significant positive result.
Standard self-attention treats every pair of edge embeddings $(e_i, e_j)$ identically in computing attention scores. But in a causal graph, the topological relationship between two edges carries strong prior information: two edges forming a chain $X \to K \to Y$ should interact differently in attention than two unrelated edges.
I define 6 topological relationship types between any pair of directed edges $(u_1 \to v_1)$ and $(u_2 \to v_2)$:
| Type | Condition |
|---|---|
| Reverse | Same pair, opposite direction |
| Shared source (fork) | $u_1 = u_2$ |
| Shared target (collider) | $v_1 = v_2$ |
| Forward chain | $v_1 = u_2$ |
| Backward chain | $v_2 = u_1$ |
| Unrelated | None of the above |
A learned scalar bias $b_\tau \in \mathbb{R}$ for each type $\tau$ is added to the attention logit before softmax:
\[A_{ij} = \frac{\mathbf{q}_i \cdot \mathbf{k}_j + b_{\tau(i,j)}}{\sqrt{d}}\]The bias weights are initialized to zero (neutral), so the model starts from standard attention and learns to prioritize certain structural relationships as training progresses. Total additional parameters: 24 scalars (6 types × 4 attention heads) - negligible.
Why this works where other architectural changes failed: Every other architectural addition I tried (cross-attention branches, dual-path transformers, node-centric pooling) degraded performance. The pattern: those changes added raw capacity without a causal prior, leading to overfitting on the 25K training set. The structural bias adds almost no capacity - it only learns how much to weight each topological relationship type, not what to look for. The inductive bias is entirely appropriate to the problem structure.
Result: 76.94% → 79.59% (+2.65% over v8b, +5.63% over baseline)
With XY augmentation: 81.14% local / 80.82% LB
 The new attention head with structural bias
The new attention head with structural bias
What Didn’t Work
These negative results are documented here because they carry genuine lessons.
ML fullstack (v13): 72.64%
I built a complete machine learning pipeline: 300+ engineered features (pairwise correlations, partial correlations, mutual information, causal discovery algorithm outputs from PC, LiNGAM, NOTEARS, ANM), four gradient boosting models, a GNN refinement stage, and a stacking ensemble.
Result: 72.64% - below the simple Conv1D baseline at 73.96%.
Why: Scalar feature compression is irreversible. Once you summarize a 1000-point conditional expectation curve into a correlation coefficient, you have permanently discarded its shape - the curvature, heteroscedasticity, and nonlinearity. That shape is exactly what distinguishes a Mediator from a Consequence of X. Conv1D reads the full curve. No amount of scalar feature engineering can recover what was thrown away.
I also tried injecting these scalar statistics as a parallel tower into the deep learning model. This also failed: broadcasting a scalar across a sequence gives it no structural relationship to the sequence positions, so the model cannot integrate it meaningfully.
Architectural complexity (v3, v4, v6, v9): regressed ~1–2%
Cross-attention branches, dual-path transformers, node-centric attention - all failed. The lesson: architectural complexity only helps when it encodes an appropriate inductive bias. General capacity additions overfit on 25K training samples.
Node-centric approaches (v9, v9b) consistently lost ~1.5% by compressing the $O(p^2)$ edge context to node-level summaries. This confirmed that full edge self-attention is load-bearing: global graph reasoning requires seeing all pairwise relationships simultaneously.
Score Progression
| Version | Local BA | LB | Key change |
|---|---|---|---|
| Baseline reimplementation | 73.96% | 73.6% | - |
| + multi-bandwidth kernel | 75.44% | 74.98% | +1.48% |
| + ANM residuals (v8b) | 76.94% | - | +1.50% |
| + XY augmentation (v8b+) | 80.26% | 80.22% | +3.32% |
| + structural bias (v11) | 79.59% | - | +2.65% over v8b |
| + XY augmentation (v11+) | 81.14% | 80.82% | best result |
Summary
Four contributions, each with a mechanistic motivation:
- Multi-bandwidth kernel channels - access to both local and global conditional structure
- ANM residual channels - direct causal direction signal, especially for Collider and Consequence classes
- XY augmentation - forces topology learning, removes positional shortcuts
- Structural attention bias - encodes causal graph priors into attention with 24 parameters
The core lesson: representational form matters more than model complexity. Full functional curves contain information that no scalar feature set can recover. Architectural changes only help when they carry an appropriate inductive bias for the problem structure - general capacity additions hurt.
What’s Next
A follow-up post will cover v26: 2D scatter density representation - replacing the 1D sorted curves with a 2D joint density histogram between variable pairs, processed by Conv2D. The framing: treating the 2D density as a visual conditional independence test. Results, caveats (translation invariance does not hold under this representation), and comparison with v11 will be covered there.
References
- thetourney. ADIA Lab Causal Discovery Challenge - 1st Place Solution. 2024. link
- mutian-hong. ADIA Lab Causal Discovery Challenge - 3rd Place Solution. 2024. link
- Hoyer, P. et al. Nonlinear Causal Discovery with Additive Noise Models. NeurIPS 2009.
- Pearl, J. Causality: Models, Reasoning, and Inference. Cambridge University Press, 2009.
- Olivetti, E. et al. Can Machines Learn Causal Structure? Evidence from ADIA Lab’s Causal Discovery Challenge. SSRN 2025.